Steps to Install Jenkins and Deploying SPARK Cluster with Zeppelin Notebook and Cassandra using Jenkins
Basic Architecture:

PRE-REQUISITES to follow before beginning with the installation:
Follow the below steps on all the nodes (for both master and slave nodes)
- Install Git on all the slave machines excluding Jenkins master since the code is pulled from github.
$ yum install –y git
- Firewall has to be disabled on all the nodes (since the spark cluster will be deployed on the jenkins slave machines),which is essential for the nodes in the spark cluster to communicate.
$ systemctl stop firewalld
$ systemctl disable firewalld
- Java has to be installed on all the nodes for Jenkins to correctly configure the slaves.
$ yum install –y java-1.8.0-openjdk-devel
- Password less ssh has to be established between Jenkins master and Jenkins slaves and also between spark master and spark slaves.
Execute these steps on jenkins master machine.
$ ssh-keygen -t rsa (Generate the ssh key).
$ ssh-copy-id <Jenkins slave machine IP>
Repeat the step 2 for all the slave machines that the jenkins master has to be connected.
Execute these steps on spark master machine.
$ ssh-keygen -t rsa (Generate the ssh key).
$ ssh-copy-id <Spark slave machine IP>
Repeat the step 2 for all the Spark slave machines that the Spark master has to be connected.
STEP 1.a : Install Jenkins [Jenkins master]
Please complete the pre-requisite before you begin with the Jenkins Installation
- Jenkins is installed in Centos using the following commands:
$ yum install java-1.8.0-openjdk-devel
$ curl –silent –location http://pkg.jenkins-ci.org/redhat-stable/jenkins.repo | tee /etc/yum.repos.d/jenkins.repo
$ rpm –import https://jenkins-ci.org/redhat/jenkins-ci.org.key
$ yum install Jenkins
$ systemctl start Jenkins
$ systemctl status Jenkins
$ systemctl enable Jenkins
After completing the above steps, copy the /root/.ssh/known_hosts file to jenkins home directory.
$ mkdir /var/lib/jenkins/.ssh
$ cp /root/.ssh/known_hosts /var/lib/jenkins/.ssh/
$ chmod 777 /var/lib/jenkins/known_hosts
- By default while installing Jenkins a user named jenkins is created with home directory /var/lib/jenkins.
- The admin password for Jenkins is present in /var/lib/Jenkins/secrets.
$ cat /var/lib/jenkins/secrets/initialAdminPassword.
- In the system where Jenkins is installed, if the system is behind a corporate network, then it asks for the proxy settings during installation.
STEP 1.b: Now add Jenkins Slaves to Jenkins Master
- We can add jenkins slaves to jenkins master using Jenkins Web UI(GUI)
Login to Jenkins Web UI from http://<master-ip-address>:8080
On Jenkins Web UI navigate to
Manage JenkinsàManage nodesànew node
Give a name for the node and select Permanent Agent and click OK
- The screen shown below should appear.

And provide appropriate details marked in red in the above figure along with the unique label for each Jenkins Slave. Also add the ssh credentials.
- Use the same label specified here in the Jenkins file. For this demo I have labelled the Spark master machine as “spark_master” and the spark slaves as “spark_slave1”,”spark_slave2” respectively. Now click on SAVE.
- Verify the installation as below by checking if all master and slave nodes are up and running:
Also click on the node name à Log and verify the details. The status should be Agent successfully connected and online.

STEP 2: Deploy Spark, Zeppelin Notebook and Cassandra using scripts from Git (https://github.com/victorcouste/zeppelin-spark-cassandra-demo) :
- Create a pipeline for a job in Jenkins, this will download the scripts to /root/scripts on all the slave nodes
Log in to Jenkins Web UI from http://<JenkinsMasterIP>:8080
Click on New Item and select pipeline and give a name.
Click OK.
Configure the job as shown below.

- The Jenkinsfile is designed to deploy a 3 node(1 master and 2 slaves) spark cluster. This should be edited as per requirements and pushed back to git or use it in jenkins job by specifying definition as pipeline Script instead of pipeline script from SCM.
- Click on SAVE.
- Click on Build Now to run the job.
- You can monitor the job by clicking on the job name > console output.
DESCRIPTION OF THE SCRIPTS
Please refer to the below table:
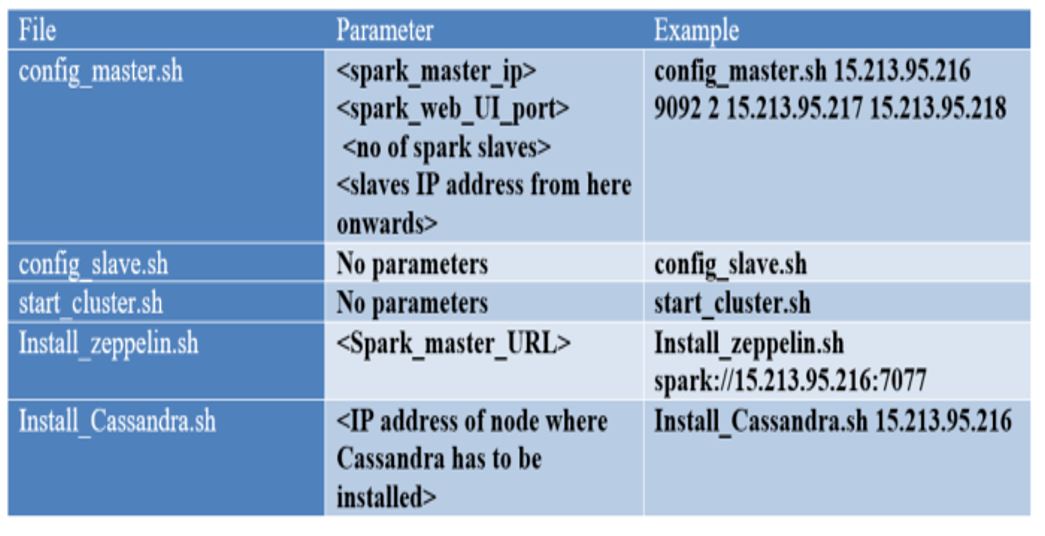
The execution of these scripts in order will form the pipeline in Jenkinsfile.
Pipeline is as described as below.

References:
https://github.com/apache/cassandra
https://cassandra.apache.org/doc/latest/cassandra/getting_started/
https://cassandra.apache.org/doc/latest/cassandra/getting_started/production.html
